Best Machine Learning Engineer 2026: The Ultimate Guide to Building an Exceptional AI Career
BlogIntroduction

Artificial intelligence is reshaping every industry on the planet. Best machine learning engineer 2026 careers represent one of the most intellectually stimulating, financially rewarding, and future-proof opportunities in technology today. Organizations worldwide are racing to implement AI solutions, creating unprecedented demand for talented professionals who can build intelligent systems.
Machine learning engineers command impressive average salaries of $145,000 annually, with senior positions at leading companies reaching $250,000 or more. The talent shortage continues intensifying as AI adoption accelerates across healthcare, finance, retail, manufacturing, and virtually every other sector imaginable.
visit our website – EasyNaukri4U – India’s Leading Government Job Portal
visit our resume builder – Government Jobs - EasyNaukri4U
“According to LinkedIn’s Global Talent Trends Report, recruiters spend an average of six to seven seconds reviewing each resume.”
At EasyNaukri4u.com, we’ve witnessed an extraordinary 520% surge in machine learning job postings over the past two years. This comprehensive guide illuminates what makes the best machine learning engineer 2026 careers so promising and provides a proven roadmap to success in this transformative field.
Understanding Machine Learning: The Foundation of Modern AI

Before pursuing the best machine learning engineer 2026 careers, you must understand what machine learning actually is and why it has become the driving force behind today’s technological revolution.
What Makes Machine Learning Revolutionary
Traditional software follows explicit instructions programmed by developers. If you want a program to recognize cats in photos, you must manually define every feature that distinguishes cats from other objects. This approach proves impossibly complex for many real-world problems where rules cannot be explicitly articulated.
Machine learning takes a fundamentally different approach. Instead of programming explicit rules, you provide examples and let algorithms discover patterns automatically. Show a machine learning model thousands of cat photos labeled as cats, and it learns to recognize cats in new images it has never seen before. This ability to learn from data rather than explicit programming enables solving problems previously considered impossible.
The power of machine learning extends far beyond image recognition. Natural language processing enables computers to understand and generate human language, powering virtual assistants, translation services, and content generation tools. Recommendation systems predict what products customers want to buy, what movies they want to watch, and what content they want to read. Predictive analytics forecast demand, detect fraud, and identify maintenance needs before equipment fails.
These capabilities create tremendous business value. Netflix estimates their recommendation system saves $1 billion annually by reducing subscriber churn. Amazon attributes 35% of revenue to recommendation algorithms. Healthcare AI detects diseases earlier than human doctors. Autonomous vehicles promise to eliminate accidents caused by human error. The applications seem limited only by imagination and available data.
Understanding this transformative potential explains why the best machine learning engineer 2026 roles command premium compensation. Companies recognize that machine learning creates competitive advantages impossible to replicate through traditional software development. Engineers who can harness this power become invaluable assets.
Types of Machine Learning Approaches
Machine learning encompasses several distinct approaches suited to different problems. Supervised learning uses labeled examples to learn mappings from inputs to outputs. Classification assigns inputs to categories like spam detection or disease diagnosis. Regression predicts continuous values like house prices or temperature forecasts. Supervised learning requires labeled training data, which can be expensive to obtain but produces highly accurate models when sufficient data exists.
Unsupervised learning discovers patterns in unlabeled data. Clustering groups similar items together, useful for customer segmentation or document organization. Dimensionality reduction compresses high-dimensional data while preserving important information. Anomaly detection identifies unusual patterns, valuable for fraud detection or quality control. Unsupervised learning finds hidden structures without requiring expensive labeling.
Reinforcement learning trains agents to make sequences of decisions maximizing cumulative rewards. The agent learns through trial and error, receiving feedback from its environment. This approach powers game-playing AI that defeats human champions, robotic control systems, and recommendation systems optimizing long-term engagement. Reinforcement learning tackles problems involving sequential decision-making that other approaches cannot address.
Deep learning uses neural networks with many layers to learn hierarchical representations of data. These models achieve remarkable performance on tasks involving images, speech, and text by automatically learning relevant features from raw data. Convolutional neural networks revolutionized computer vision. Recurrent networks and transformers transformed natural language processing. Deep learning drives most recent AI breakthroughs.
Understanding these fundamental approaches enables choosing appropriate techniques for specific problems. The best machine learning engineer 2026 professionals match algorithms to problems thoughtfully rather than applying trendy techniques indiscriminately.
Visit EasyNaukri4u.com to explore exciting machine learning positions across industries embracing AI innovation.
Essential Technical Skills for Machine Learning Excellence

Success in the best machine learning engineer 2026 careers requires mastering mathematical foundations, programming skills, and practical engineering abilities.
Mathematical Foundations
Linear algebra provides the mathematical framework for machine learning. Vectors represent data points and feature sets. Matrices represent datasets and model parameters. Operations like matrix multiplication, eigenvalue decomposition, and singular value decomposition appear throughout machine learning algorithms. Understanding linear transformations helps interpret what models actually compute.
Calculus enables optimization, the process of finding parameters that minimize prediction errors. Gradient descent iteratively adjusts parameters following the gradient of the loss function toward minimum error. Partial derivatives indicate how changing each parameter affects overall performance. Chain rule enables computing gradients through complex compositions of functions, essential for training deep neural networks through backpropagation.
Probability and statistics provide frameworks for reasoning under uncertainty. Probability distributions model uncertainty in data and predictions. Bayes’ theorem enables updating beliefs based on evidence. Statistical inference draws conclusions from limited samples. Maximum likelihood estimation finds parameters making observed data most probable. These concepts underlie virtually every machine learning algorithm.
Information theory quantifies information content and uncertainty. Entropy measures uncertainty in probability distributions. Cross-entropy serves as loss function for classification. Mutual information quantifies dependencies between variables. These concepts inform feature selection, model evaluation, and understanding model behavior.
While advanced mathematics isn’t required for every machine learning task, strong foundations enable deeper understanding and innovation. Engineers who understand why algorithms work can adapt them creatively to novel problems. Those who only know how to apply algorithms struggle when standard approaches fail.
Programming and Software Engineering
Python dominates machine learning development. Its readable syntax, extensive libraries, and vibrant community make it ideal for ML work. Understanding Python deeply including object-oriented programming, functional programming, generators, decorators, and package management enables effective development. Writing clean, maintainable Python code demonstrates professionalism.
NumPy provides efficient numerical computing with multi-dimensional arrays. Vectorized operations execute much faster than Python loops. Understanding broadcasting, slicing, and array operations enables efficient computation. NumPy serves as foundation for virtually all scientific Python libraries.
Pandas handles structured data manipulation and analysis. DataFrames organize tabular data with labeled rows and columns. Powerful operations for filtering, grouping, joining, and reshaping data enable efficient data preparation. Most real-world ML projects spend significant time in data preparation where Pandas skills prove essential.
Scikit-learn offers comprehensive machine learning algorithms with consistent interfaces. Classification, regression, clustering, dimensionality reduction, and model selection tools cover most traditional ML needs. Understanding Scikit-learn patterns for training, prediction, and evaluation transfers across algorithms. The library’s documentation provides excellent learning resources.
Deep learning frameworks enable building and training neural networks. PyTorch offers dynamic computation graphs and Pythonic interface preferred by researchers. TensorFlow provides production-ready infrastructure with TensorFlow Extended for ML pipelines. Understanding at least one framework deeply while being familiar with alternatives enables working across different environments.
Software engineering practices ensure code quality and reproducibility. Version control with Git tracks changes and enables collaboration. Testing validates code correctness. Documentation explains usage and design decisions. Clean code organization separates concerns appropriately. These practices distinguish professional engineers from hobbyists.
Data Engineering Fundamentals
Machine learning requires data pipelines collecting, processing, and serving data. Understanding SQL for querying relational databases enables accessing most enterprise data. NoSQL databases like MongoDB handle unstructured data. Data warehouses aggregate data for analysis. Cloud data services provide scalable storage and processing.
Feature engineering transforms raw data into representations useful for models. Understanding domain-specific transformations, encoding categorical variables, handling missing values, and creating derived features significantly impacts model performance. Feature engineering often contributes more than algorithm selection to success.
Data validation ensures data quality before training models. Schema validation catches structural problems. Statistical tests detect distribution shifts. Data versioning tracks changes enabling reproducibility. Proper validation prevents garbage-in-garbage-out scenarios where models learn from corrupted data.
MLOps practices manage the machine learning lifecycle. Experiment tracking records hyperparameters and metrics. Model registries version trained models. Feature stores provide consistent feature computation. Monitoring detects model degradation in production. These practices enable reliable ML systems at scale.
Check EasyNaukri4u.com for positions requiring these valuable skills and offering excellent compensation packages.
Deep Learning and Neural Networks
Deep learning powers the most impressive AI achievements and represents essential knowledge for the best machine learning engineer 2026 careers.
Understanding Neural Network Fundamentals
Neural networks consist of layers of interconnected nodes loosely inspired by biological neurons. Input layers receive data. Hidden layers transform representations. Output layers produce predictions. Connections between nodes have learnable weights adjusted during training to minimize prediction errors.
Activation functions introduce nonlinearity enabling networks to learn complex patterns. ReLU (Rectified Linear Unit) has become standard for hidden layers due to computational efficiency and gradient properties. Sigmoid and softmax convert outputs to probabilities for classification. Understanding activation functions helps diagnose training problems and design appropriate architectures.
Backpropagation computes gradients of loss with respect to parameters using the chain rule. These gradients indicate how to adjust weights to reduce errors. Gradient descent updates parameters iteratively in directions reducing loss. Stochastic gradient descent uses minibatches for efficient training on large datasets. Optimizers like Adam adapt learning rates for faster convergence.
Regularization prevents overfitting where models memorize training data rather than learning generalizable patterns. Dropout randomly deactivates neurons during training, forcing redundant representations. Weight decay penalizes large weights. Batch normalization stabilizes training. Early stopping halts training when validation performance degrades. Effective regularization enables models to generalize to new data.
Convolutional Neural Networks for Computer Vision
Convolutional neural networks (CNNs) revolutionized computer vision. Convolutional layers apply learnable filters detecting local patterns like edges and textures. Pooling layers reduce spatial dimensions while preserving important features. Stacking convolutional and pooling layers builds hierarchical representations from simple edges to complex objects.
Famous architectures provide blueprints for visual tasks. AlexNet demonstrated deep learning’s potential by winning ImageNet competition. VGG showed that deeper networks with small filters improve performance. ResNet introduced skip connections enabling extremely deep networks. EfficientNet optimizes architecture for computational efficiency. Understanding these architectures and their innovations informs design decisions.
Transfer learning leverages models pretrained on large datasets. Instead of training from scratch, you start with weights learned on ImageNet and fine-tune for specific tasks. This dramatically reduces data requirements and training time. Most practical computer vision projects use transfer learning.
Object detection locates and classifies multiple objects in images. YOLO (You Only Look Once) provides real-time detection. Faster R-CNN offers higher accuracy. Semantic segmentation classifies every pixel. Instance segmentation identifies individual object instances. These techniques enable applications from autonomous driving to medical imaging.
Natural Language Processing and Transformers
Transformers revolutionized natural language processing and now influence computer vision and other domains. Attention mechanisms enable models to focus on relevant parts of input when producing each output element. Self-attention relates different positions within sequences, capturing long-range dependencies more effectively than recurrent networks.
BERT (Bidirectional Encoder Representations from Transformers) learns contextual word representations through masked language modeling. Pretrained BERT embeddings dramatically improve performance on downstream tasks with limited labeled data. Fine-tuning BERT for classification, question answering, or named entity recognition follows straightforward patterns.
GPT (Generative Pre-trained Transformer) models excel at text generation. Training on massive text corpora enables generating remarkably coherent and contextually appropriate text. GPT-4 and similar models power conversational AI, content generation, and code assistance tools. Understanding how these models work helps leverage them effectively.
Large language models (LLMs) require special consideration for deployment. Their massive size demands significant computational resources. Prompt engineering crafts inputs eliciting desired outputs. Fine-tuning adapts models to specific domains. Retrieval-augmented generation grounds responses in external knowledge. These techniques optimize LLM applications.
Building Your Professional Portfolio
Demonstrating practical skills through impressive project work proves essential for landing the best machine learning engineer 2026 positions.
Essential Portfolio Projects
Building an end-to-end image classification system demonstrates computer vision fundamentals. Collect or curate a dataset for a specific classification task. Implement data augmentation to improve generalization. Train a CNN using transfer learning from pretrained models. Evaluate performance using appropriate metrics. Deploy the model as a web service or mobile application. This project showcases the complete machine learning workflow.
Creating a natural language processing application shows text handling abilities. Build a sentiment analyzer for product reviews or social media. Implement text classification for document categorization. Create a question-answering system using transformer models. Add functionality like named entity recognition or text summarization. NLP projects demonstrate valuable and marketable skills.
Developing a recommendation system exhibits understanding of personalization. Implement collaborative filtering using matrix factorization. Add content-based recommendations using item features. Create hybrid approaches combining multiple signals. Evaluate using offline metrics and consider A/B testing approaches. Recommendation systems power many consumer applications.
Building a time series forecasting project shows predictive capabilities. Forecast demand, stock prices, or resource utilization. Implement classical methods like ARIMA alongside machine learning approaches. Handle seasonality, trends, and irregular patterns. Evaluate forecasts appropriately considering business context. Time series projects apply across industries.
Creating an end-to-end ML pipeline demonstrates production engineering skills. Implement data ingestion, validation, and preprocessing. Add feature engineering and feature store integration. Include experiment tracking and model versioning. Build serving infrastructure with monitoring. Document everything thoroughly. Pipeline projects show you understand real-world ML engineering.
Contributing to Open Source
Participating in open-source machine learning projects builds credibility and connections. Major frameworks like PyTorch, TensorFlow, and Scikit-learn welcome contributions. Start with documentation improvements or bug fixes if you’re new to the codebase. Progress to implementing new features or algorithms as you gain familiarity.
Many machine learning engineers discovered job opportunities through open-source contributions. Maintainers often hire contributors who’ve demonstrated ability through sustained participation. The public nature of open-source work creates transparent evidence of your capabilities.
Creating your own open-source tools or libraries demonstrates initiative. Implement useful utilities solving common problems. Publish model implementations making research accessible. Build educational resources helping others learn. Even small packages with focused functionality establish expertise.
Kaggle Competitions
Kaggle competitions provide structured machine learning challenges with leaderboards measuring performance. Participating develops practical skills applying algorithms to real datasets. Studying winning solutions reveals advanced techniques and creative approaches.
Strong Kaggle rankings signal competence to employers. Reaching Expert or Master tier demonstrates proven ability. Even participating without top rankings shows initiative and learning. Competition experience develops intuition about what works in practice.
Writing competition solutions as detailed blog posts multiplies the value. Explaining your approach demonstrates communication skills. Sharing insights helps the community. Published analyses become portfolio pieces showcasing thought process beyond just code.
Visit EasyNaukri4u.com to find positions valuing demonstrated machine learning project experience.
Career Paths and Outstanding Opportunities

The best machine learning engineer 2026 field offers diverse career trajectories with excellent compensation and continuous intellectual challenge.
Junior Machine Learning Engineer Positions
Entry-level positions paying $90,000-$120,000 annually focus on building foundational skills while contributing to team success. You’ll implement models from specifications, prepare and clean datasets, run experiments varying hyperparameters, evaluate model performance, and document processes. Junior roles involve significant learning while producing real value.
Companies hiring junior ML engineers value strong fundamentals over extensive experience. Solid mathematics, good programming practices, completed projects, and genuine curiosity matter more than years worked. Many successful careers begin with internships or rotational programs at companies investing in talent development.
Machine Learning Engineer Positions
Mid-level engineers earning $120,000-$160,000 annually own significant components of ML systems. You’ll design model architectures for new problems, develop training pipelines handling large datasets, optimize models for performance and efficiency, deploy models to production, and mentor junior team members. This level requires independent problem-solving and technical leadership.
Successful mid-level engineers balance technical excellence with business impact awareness. Understanding why particular problems matter and how solutions create value distinguishes professionals from pure technicians. Communication skills become increasingly important as you collaborate across teams and explain technical concepts to stakeholders.
Senior Machine Learning Engineer Roles
Senior engineers commanding $160,000-$200,000+ architect ML solutions and set technical direction for their organizations. You’ll design end-to-end ML systems handling scale and complexity, make strategic technology decisions, establish best practices and standards, evaluate build versus buy decisions, and influence product roadmaps. This role requires broad knowledge and deep expertise in specialized areas.
Senior engineers often specialize in domains like computer vision, NLP, recommendation systems, or MLOps. Your expertise guides important decisions and prevents costly mistakes. Strong communication becomes essential as you influence strategy beyond just implementing solutions. Many senior engineers present at conferences, publish papers, or contribute to open source.
Research Scientist and Principal Engineer Positions
Research scientists earning $180,000-$300,000+ advance the state of the art through novel research. You’ll identify important unsolved problems, develop new algorithms and architectures, run experiments validating hypotheses, publish findings in peer-reviewed venues, and translate research into products. This path typically requires PhD-level training and sustained research productivity.
Principal engineers at similar compensation levels drive technical excellence across organizations. You’ll define technical roadmaps spanning multiple teams, make architectural decisions with company-wide impact, mentor senior engineers, evaluate emerging technologies, and solve problems others cannot. This level requires recognized expertise demonstrated through years of impactful work.
ML Leadership Roles
ML managers and directors earning $180,000-$280,000 build and lead teams of machine learning professionals. You’ll hire and develop talent, set team strategy aligned with business goals, allocate resources across projects, remove obstacles for your team, and communicate with executives. Leadership roles suit those who find satisfaction in enabling others’ success.
VP and C-level ML roles at the largest companies exceed $300,000 with significant equity. You’ll define organization-wide AI strategy, make major investment decisions, represent the company externally, and shape company direction. These positions require exceptional track records and leadership abilities.
Explore these exceptional opportunities at EasyNaukri4u.com where leading companies actively seek talented machine learning professionals.
Learning Roadmap: Your Powerful 90-Day Plan
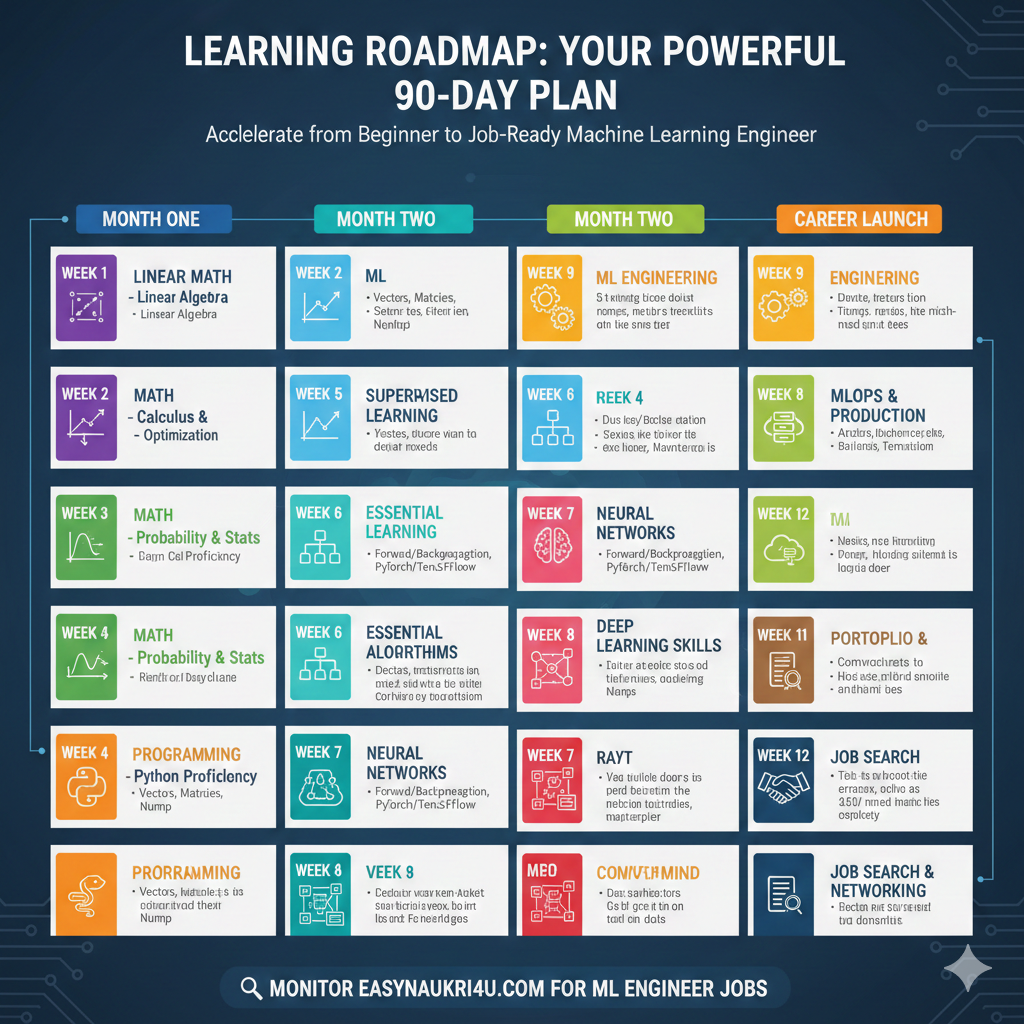
This intensive roadmap transforms motivated beginners into job-ready machine learning engineers through focused daily practice and progressive skill building.
Month One: Mathematical and Programming Foundations
Week one establishes essential mathematical foundations. Review linear algebra focusing on vectors, matrices, operations, and geometric interpretations. Study resources like 3Blue1Brown’s linear algebra series for intuitive understanding. Practice implementing matrix operations in NumPy. Strong linear algebra intuition helps interpret machine learning algorithms.
Week two covers calculus and optimization. Review derivatives, partial derivatives, and the chain rule. Understand gradient descent geometrically as moving downhill on loss surfaces. Implement gradient descent from scratch for simple functions. This foundation enables understanding how neural networks learn.
Week three focuses on probability and statistics. Review probability distributions, expectation, variance, and conditional probability. Study Bayes’ theorem and its applications. Understand maximum likelihood estimation. Practice with statistical computations using Python. These concepts underlie virtually every ML algorithm.
Week four builds Python programming proficiency. Complete comprehensive Python tutorials covering object-oriented programming, functional programming patterns, and idiomatic Python. Practice with NumPy and Pandas for numerical computing and data manipulation. Implement simple algorithms from scratch. Strong programming skills accelerate all future learning.
Month Two: Core Machine Learning
Week five introduces supervised learning fundamentals. Study linear regression understanding the mathematics and implementation. Progress to logistic regression for classification. Implement both from scratch, then use Scikit-learn. Understand evaluation metrics appropriate for regression and classification.
Week six covers essential algorithms. Study decision trees understanding how they split data. Learn ensemble methods like random forests and gradient boosting. Understand support vector machines conceptually. Practice applying these algorithms to datasets using Scikit-learn. Compare performance across algorithms.
Week seven introduces neural networks and deep learning. Study perceptrons and multilayer networks. Understand forward propagation and backpropagation mathematically. Implement a simple neural network from scratch. Then use PyTorch or TensorFlow for the same task. This progression builds understanding beneath framework abstractions.
Week eight develops deep learning skills further. Study convolutional neural networks for computer vision. Understand recurrent networks and attention mechanisms for sequences. Implement image classification using transfer learning. Build a text classification model using transformers. Complete tutorials from framework documentation.
Month Three: Advanced Topics and Career Launch
Week nine covers practical ML engineering. Study feature engineering techniques for different data types. Learn data validation and quality practices. Understand model selection and hyperparameter tuning. Practice building complete pipelines from raw data to predictions.
Week ten focuses on MLOps and production. Study experiment tracking using tools like MLflow. Understand model deployment options. Learn monitoring for detecting model degradation. Practice containerizing models with Docker. These skills bridge the gap between prototype and production.
Week eleven prepares your portfolio and materials. Polish your best projects with documentation and deployment. Create a professional portfolio website. Update your resume highlighting ML experience. Prepare to discuss projects in detail during interviews.
Week twelve activates your job search. Apply to positions matching your skill level. Reach out to ML professionals for informational interviews. Practice technical interviews including coding and ML concepts. Attend meetups and conferences for networking.
Monitor EasyNaukri4u.com throughout your journey for machine learning engineer positions matching your growing capabilities.
Conclusion: Your Machine Learning Journey Begins Today
The best machine learning engineer 2026 careers offer remarkable opportunities for intellectually curious problem-solvers passionate about building intelligent systems. The combination of strong demand, excellent compensation, and meaningful work makes this field exceptionally attractive for ambitious technologists.
Success requires dedication to continuous learning as the field advances rapidly. New architectures, techniques, and tools emerge constantly. Engineers who embrace lifelong learning thrive while those resisting change fall behind. The dynamic nature keeps work engaging while rewarding those who stay current with developments.
Start your journey today by taking one concrete action. Install Python and complete a basic tutorial. Work through a linear algebra refresher. Run your first machine learning model on a sample dataset. Each small step builds momentum toward your goal of becoming a professional machine learning engineer.
Machine learning transforms how businesses operate and how people live. Healthcare AI saves lives through earlier diagnosis. Recommendation systems connect people with content they love. Autonomous systems increase safety and efficiency. Your work as a machine learning engineer will contribute to this transformation while building a rewarding career.
Visit EasyNaukri4u.com today to explore current machine learning engineering opportunities. Your amazing career building intelligent systems that solve real problems awaits. The future of AI is being created now—be one of the engineers shaping it!